- LLM 장단점과 대표 모델

- 12-27
- TECH

- AI는 크게 Vision(이미지 및 영상)과 NLP(언어)로 나뉘는데 LLM은 NLP(Natural Language Processing)에 해당되며, Large Language Model의 약자로 대규모 언어 모델을 뜻합니다.
- 인간과 유사한 텍스트를 처리, 이해 및 생성하도록 설계된 고급 인공 지능(AI) 시스템입니다.
- 딥러닝 기술 기반이며 웹 사이트, 책, 기사와 같은 다양한 소스에서 수십억 개의 단어를 포함하는 대규모 데이터 세트에서 훈련됩니다.
- 언어, 문법, 문맥 및 일반 지식의 뉘앙스를 파악할 수 있습니다.
- 응답 질문
- 텍스트 요약
- 언어 번역
- 콘텐츠 생성
- 사용자와의 양방향 대화(챗봇)
- - Meta AI에서 개발한 오픈소스 LLM
- - 가장 인기있는 오픈소스이고 2023년 7월 18일에 상용
- - 2024년 4월 18일 라마 3 출시
- - 7B에서 70B까지 네 가지 크기를 제공
- - llama 1보다 더 큰 2조 개의 토큰으로 구성되어 있음
- - 표준 트랜스포머 아키텍처 활용 -> RMSNorm(Root Mean Square layer normalization), RoPE(Rotary Positional Embedding)과 같은 새로운 기능 적용
- - Supervised fine-tuning(미세조정)으로 시작하여 RLHF(휴먼 피드백을 통한 강화학습)를 통해 개선됨
- - tokenizer: Byte Pair Encoding(BPE) 알고리즘과 SentencePiece 사용
- - Mistral AI가 출시한 모델로 맞춤형 학습과 튜닝 및 데이터 처리 방법을 기반으로 생성됨
- - Apache 2.0 라이선스로 제공되는 오픈 소스 모델
- - 실제 애플리케이션에 적용할 수 있게 설계되어 효율적이며 높은 성능 제공
- - 수학, 코드 생성 및 추론을 포함한 다양한 벤치마크에서 뛰어난 성능 발휘
- - Mistral-7B: tiny 모델로 복잡한 계산이 없는 대용량 batch 처리 작업에 적합, 애플리케이션에 가장 비용 효율적
- - 업스테이지에서 출시한 소형 언어모델
- - 107억 개의 매게변수로 이루어짐
- - 필수적인 NLP(자연어 처리) 작업에서 더 나은 성능을 발휘하면서도 효율성을 유지하는 최신이자 오픈소스 LLM
- - 2023년 12월 세계 최댛 머신러닝 플랫폼인 허깅페이스가 운영하는 '오픈 LLM 리더보드'에서 1위 달성
- - sLLM의 기준이라고 할 수 있는 300억 매개변수(30B) 이하 사이즈로 글로벌 최고 성능 모델에 오름
- - 자체적으로 구축한 데이터 적용 및 자체 스케일링 기법(Depth Up-Scaling) 활용
- - 사전 학습 및 파인튜닝 단계에서 리더보드 벤치마킹 데이터셋을 활용하지 않음 자체적으로 구축한 데이터 적용
- - 8개월만에 10억 달러 이상의 가치를 인정받으며 유니콘 기업으로 성장한 중국 스타트업 01.AI가 개발
- - 다국어 모델을 목표로 모델 학습에 고품질의 3T 다국어 코퍼스 활용
- - 이해력, 상식 추론, 독해력 등에서 주목할만한 성능을 보임
- - LLaMA와 동일한 모델 아키텍처 활용
- - 6B 및 34B 크기의 모델 제공/ 추론 시간 동안 32K 확장 가능
- - 6B: 개인용 및 학술용으로 적합
- - 34B: 상업용 및 개인용, 학술용으로 적합
- - 아랍에미리트(UAE)의 기술혁신연구소에서 출시한 생성형 대규모 언어 모델
- - 180B, 40B, 7.5B, 1.3B 파라미터의 AI 모델 제공
- - 40B:
- - 연구자와 상업 사용자 모두에게 로열티 없이 제공되고 있음
- - 11개의 언어로 작동 가능/ 특정 요구사항에 맞게 파인튜닝 가능
- - GPT-3 보다 적은 훈련 컴퓨팅리소스를 사용하며 품질 높은 훈련 데이터에 초점을 맞춤
- - 180B:
- - 1800억 개의 파라미터 보유/ 3.5조 개의 토큰을 훈련하여 탁월한 성능을 발휘
- - 40B:

LLM이란?
LLM 데이터 코퍼스 구축의 필수 요소데이터 코퍼스: 말뭉치/ 자연어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합
1. 수량보다 데이터 품질 우선시
- 광범위하지만 체계적이지 않은 데이터에 대해 훈련된 모델은 부정확한 결과를 낳을 수 있음.
- 더 작고 세심하게 선별된 데이터 세트는 종종 우수한 성능을 보임.
2. 적절한 데이터 소스 선택
- 대화 생성 모델에서 대화 및 인터뷰 소스 활용하기
- 코드 생성 초점 모델은 잘 문서화된 코드 저장소의 이점 활용 등
3. 합성 데이터 생성 사용
- 합성 데이터로 데이텟을 강화하면, 훈련 데이터셋의 다양성을 확대하여 모델의 탄력성을 향상시키고 편향을 줄일 수 있음
4. 자동화된 데이터 수집 구현
2024년에 주목해야할 LLM 오픈소스 모델
1. Llama 2
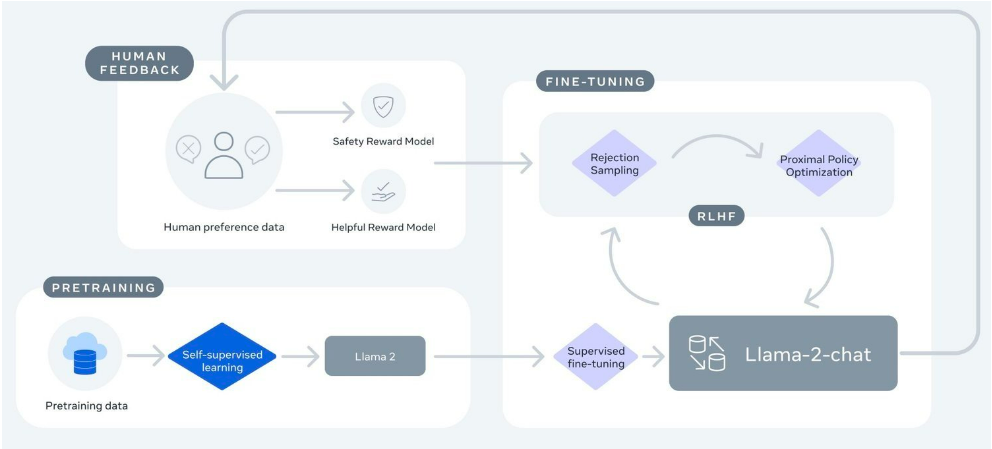
인간 피드백을 통한 강화학습(RLHF)과 보상 모델링을 통해 양방향 대화에 최적화한 LLaMA 21-Chat(출처: Meta AI)
2. Mistral
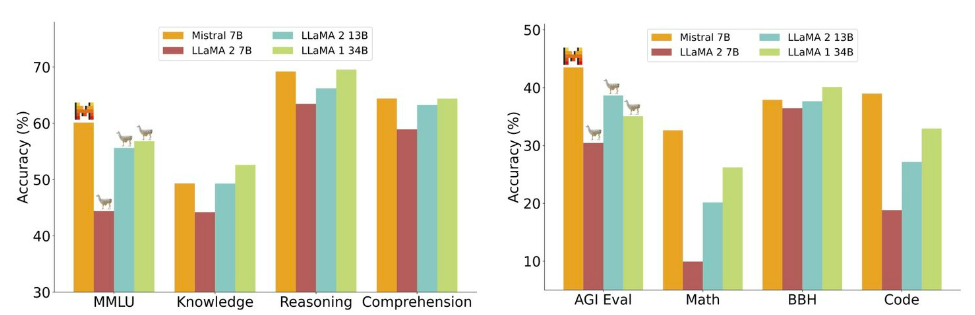
다양한 벤치마크에서 Mistral 7B와 Llama 모델의 성능 비교
3. Solar
4. Yi
5. Falcon
LLM의 장점
1. 광범위한 지식 활용
- 방대한 양의 텍스트 데이터를 학습하여 다양한 분야의 지식을 습득
- 학습한 지식을 바탕으로 사용자의 질문에 폭넓고 심도 있는 답변 가능
2. 뛰어난 언어 이해 및 생성 능력
- 단어 간의 관계와 문맥을 고려하여 자연스러운 언어 이해 가능
- 문법적으로 정확하고 의미 있는 문장 생성 능력
3. 다양한 태스크 수행 가능
- 텍스트 분류, 질의응답, 요약, 번역, 문장 생성 등 다양한 NLP 태스크 처리 가능
- 하나의 모델로 여러 태스크를 수행할 수 있어 범용성이 높음
4. 사용자 친화적인 인터페이스
- 자연어로 된 사용자 입력을 이해하고 응답할 수 있어 접근성이 좋음
- 챗봇, 가상 어시스턴트 등으로 활용되어 사용자 경험 향상
5. 다양한 분야에서의 활용
- 고객 서비스, 콘텐츠 제작, 교육, 의료 등 다양한 산업 분야에서 활용 가능
- 사람과 기계 간의 상호작용을 향상시키고 업무 효율성 증대에 기여
LLM의 단점
1. 편향성 문제
- 학습 데이터에 내재된 편향성을 그대로 반영할 수 있음
- 성별, 인종, 종교 등에 대한 고정관념이나 차별적 표현을 생성할 위험 존재
2. 사실 관계 오류 가능성
- 방대한 데이터를 학습하지만, 항상 정확한 정보를 제공하지는 않음
- 잘못된 정보나 허위 정보를 진실로 간주하고 전파할 수 있음
3. 맥락 이해의 한계
- 문장 단위의 이해는 가능하지만, 장문의 글이나 복잡한 맥락 파악은 어려울 수 있음
- 세계 지식과 상식 추론 능력이 부족하여 심층적인 이해에 한계 존재
4. 일관성 문제
- 동일한 입력에 대해 일관된 답변을 생성하지 않을 수 있음
- 모델의 확률적 특성상 생성 결과가 매번 달라질 수 있어 신뢰성 저하
5. 윤리적 문제
- 악용 가능성이 존재하며, 책임 소재 파악이 어려울 수 있음
- 모델의 출력 결과에 대한 통제와 검증 체계 마련 필요
※ LLM의 단점 중 ‘사실 관계 오류 가능성’과 ‘맥락 이해의 한계’를 개선하는 데 초점을 맞춘 것이 바로 RAG(Retrieval-Augmented Generation)입니다. 다음 시간에는 RAG에 대한 내용으로 찾아뵙겠습니다!


